浮動小数点とメモリイメージ(16進数文字列、HEX文字列、)の変換について →からの→ splitについて(再掲)
「見たまま編集」から「markdown記法」に更新しました...
いきさつ
>ほかにも javascriptで変換する物 とかあったのですが、
>また別途書くことにします。
ということで書いていきます。
#変換するだけならリンク先にどうぞ・・・
引用
今回調べたのは javascriptで変換する物 から引用した下記です。
var arrayClass = { 8: Float32Array, 16: Float64Array }; function calcDecimalFromBinary(value, nByte) { var buffer = new Uint8Array( (value + "0000000000000000").substr(0, nByte) .split(/(.{2})/) .map(function (b) { return parseInt(b, 16); } ).filter(isFinite).reverse()).buffer; return (new arrayClass[nByte](buffer))[0]; }
浮動小数点(数値)からメモリイメージ(16進数文字列、HEX文字列、)への変換に Float64Array を使っているだけなので、詳細はリンク先を確認ください。
本題
そしてやっと本題ですが、
読み下したときに意味不明だった「split(/(.{2})/)」について調べてみました。
まず MDN の split の説明 を見る・・・
引用した「split(/(.{2})/)」と同じような書き方はサンプルに登場せず、もやもやした感じが解決しません。
説明から動作を解明するのをあきらめて実際の動作を見ることにしました。
動作解析の準備
やりすぎた感じもありますが、処理中の結果をモニタ出来るように変更してみました。
function calcDecimalFromBinary(value, nByte) { var buf1 = (value + "0000000000000000"); var buf2 = buf1.substr(0, nByte); var buf3 = buf2.split(/(.{2})/); var sub_func = function (b) { return parseInt(b, 16); }; var buf4 = buf3.map(sub_func); var buf5 = buf4.filter(isFinite); var buf6 = buf5.reverse(); var buffer = new Uint8Array( buf6 ).buffer; return (new arrayClass[nByte](buffer))[0]; }
動作の説明
(1)「(value + "0000000000000000")」と「.substr(0, nByte)」で、入力されたHEX文字列を「nByte」の長さにそろえています。
(2)問題の「.split(/(.{2})/)」ですが・・・HEX文字列を分割している様子です。
(3)「function (b) { return parseInt(b, 16); };」を「.map()」の引数にセットして分割したHEX文字列を数値に変換しています。
(4)「.filter()」は、配列の要素をテストしてテストに合格した要素を抽出します。 「isFinite」は渡された値が有限数かどうかを判定します。 つまり、「.filter(isFinite)」は配列の数値だけを抽出する記述となります。
・・・なぜ必要なのか不明でしたが「.split(/(.{2})/)」の出力に関係がありました。
buf2 = '0102030405060708' としたとき、
buf3 = [,'01',,'02',,'03',,'04',,'05',,'06',,'07',,'08',]
buf4 = [NaN,1,NaN,2,NaN,3,NaN,4,NaN,5,NaN,6,NaN,7,NaN,8,NaN]
buf5 = [1,2,3,4,5,6,7,8] となり、NaNを取り除く必要があるためでした。
一応最後まで解説すると、
(5)「.reverse()」で、配列の順番を逆転します。 結果は「buf6」です。
(6)「buffer = new Uint8Array( buf6 ).buffer;」で、型なし配列から型付き配列( 8 ビット符号なし整数値)を得ています。
(7)「return (new arrayClass[nByte](buffer))[0];」で、型付き配列( 8 ビット符号なし整数値)から数値(浮動小数点)の配列を得て、その先頭要素を結果としてreturnしています。
※「arrayClass[nByte]、nByte=16」から「Float64Array」が得られるので読み替えを実施してから考えるとよいです。
まとめ
文字列を文字数で分割する際に「文字列の分割」の語感に惑わされて?「.split(/(.{2})/)」を使うと、
後で「.filter(isFinite)」等の空き要素を省く処理が必要な場合があります。
これに対応する私のおすすめは「.match(/(.{2})/g)」を使用することです。
引用した例の場合は「var buf3 = buf2.match(/(.{2})/g);」の様に変更すると、
buf3 = ['01','02','03','04','05','06','07','08'] となるので、「.filter(isFinite)」等の空き要素を省く処理が不要になります。
※文字数は、実際の処理に合わせて書き換えてください。
※MDN の match の説明 を参照してください。
wsh(.wsf、Windows Script File)のスクリプトを育てる(1)
wshの書き方と起動方法
webで調べると*.vbs、*.js、*.wsfの三種類が挙がってくるが、
スクリプトをダブルクリックで起動したときにWScript.echoを使ったらダイアログに出力されます。
【vbsの例】 ... sample_wsh1.vbsで保存&実行してみましょう
WScript.Echo "hello!!"
【jsの例】 ... sample_wsh1.jsで保存&実行してみましょう
WScript.Echo("hello!!");
これはこれでとっつきやすくて良いのですが、
少しづつ込み入った事をやろうとしてデバッグ用の出力を追加すると途端に面倒なことになってきます。
ここで対策として思いつくのはバッチファイルでcscriptを使う方法です。
【batの例】 ... sample_wsh1.batで保存&実行してみましょう
cscript sample_wsh1.vbs pause
または
cscript sample_wsh1.js pause
これもこれでとっつきやすくて良いのですが、 ファイルが2個になって面倒な感じがしませんか? しますよね?
ここでお勧めするのは拡張子がwsfのスクリプトです。
しかしひとまずはhello!!を表示させるスクリプトをwsfの書き方にしてみましょう。
【wsf(vbs)の例】 ... sample_wsh2.wsfで保存&実行してみましょう
<job> <script type="text/javascript"> WScript.echo("hello!!"); </script> </job>
【wsf(js)の例】 ... sample_wsh3.wsfで保存&実行してみましょう
<job> <script language="vbscript"> WScript.Echo "hello!!" </script> </job>
※スクリプトの種類について、
vbsはlanguage="vbscript"しか受け付けない様子です。
また、
jsはtype="text/javascript"とlanguage="javascript"が受け付けられるみたいです。
(ブログを記入した時点:2023-04-02)
wshを必ずcscriptで実行する
いろいろな仕掛けが満載なのですが、とりあえず結果を見てみましょう。
【wsfの例】 ... sample_wsh4.wsfで保存&実行してみましょう
※以下のscript要素の中身はjavascriptで書いていきます。
<?xml version="1.0" encoding="UTF-8" ?> <package> <job id='start'> <script type="text/javascript"> var wss = new ActiveXObject("WScript.Shell"); wss.Run('cmd /k cscript //nologo //job:main ' + WScript.ScriptFullName, 1, false); </script> </job> <job id='main'> <script type="text/javascript"> WScript.echo("hello!!"); </script> </job> </package>
スクリプトの実行結果は以下のような感じです。

wshを必ずcscriptで実行する方法の解説
<?xml version="1.0" encoding="UTF-8" ?>
wsfファイルは基本的にxml形式なのでトラブル防止のためにおまじないを書いておく。<package>と</package>
複数のjobを記述する場合は、<package>~</package>で囲む必要があります。<job id='start'>と<job id='main'>
複数のjobを使い分ける場合には、jobを識別するためのidを設定する必要がある。
cscriptのコマンドラインオプションに//job:mainの様に書いて実行するjobを指示できる。
cscriptのコマンドラインオプションでjobを指示しない場合は先頭に書いたjobが実行される。
上記サンプルsample_wsh4.wsfの場合は//job:startを指示するのと同じである。
job id='start' の解説
もう少しでゴールが見えてきました。
var wss = new ActiveXObject("WScript.Shell");
//job:startから//job:mainを起動するためにActiveXObjectオブジェクトを準備しています。
※wshで準備されて使用できるWScriptオブジェクトとActiveXObject(WScript.Shell)が全く同じ綴りなので混同しそうになりますが別モノなので注意しましょう。wss.Run(実行文字列, 1, false);
ActiveXObject(WScript.Shell)のrunメソッドで別プロセスを起動している。- 別プロセスの実行文字列(引数1)
- ウィンドウ通常アクティブ(引数2)
- 終了待ち無し(引数3)
実行文字列(前)
'cmd /k cscript- cmd.exeでcscript.exeを実行
- cscript.exe終了後にプロンプトで待つ
実行文字列(後)
//nologo //job:main ' + WScript.ScriptFullName
cscript.exeの引数です。
job id='main' の解説
※前半で説明した通り「hello!!」を出力する記述です。
まとめ
これでexplorerでダブルクリックしたスクリプト(.wsfファイル)がコマンドプロンプトで実行される様になりました。
参考
CSSによる書式の変更がうまくいかないときに調べること
いきさつ
はてなブログでは選択したテーマでブログが表示されますが、それをカスタマイズするためにCSSを書くことができます。
※デザインCSSの説明を参照
これが当初上手くいかなかったのでいろいろ調べましたが、いろいろな都合で正解が変化することがある様子なので、調査方法をメモすることにしました。
#EdgeやChromeが世の中の主流かもしれませんが、ここは私が普段使っているfirefoxで書いていきます。
前回書いた はてなブログの備忘録 - hs20230321のブログ の、
>※デフォルトの行間が広すぎるので設定した。
>※検索したwebで見つけた記述「.entry-content p {」ではうまくいかず、さらに探した結果「.entry .entry-content p {」とした。
という部分ですね・・・・
調査ツールを起動
とりあえず調査ツールを起動しましょう。
調査したいwebページの上にマウスカーソルを置いて、マウス右ボタンメニューから「調査」です。
#EdgeやChromeも同様に起動できると思われますので調べてみましょう・・・

ブラウザの下を区切って調査ツールが起動しました。

調査したいhtml要素を選択
次に調査したいhtml要素を選択します。
調査ツールの左側に表示されているhtml要素を選択すると、

html要素に対応する領域が強調表示されます。
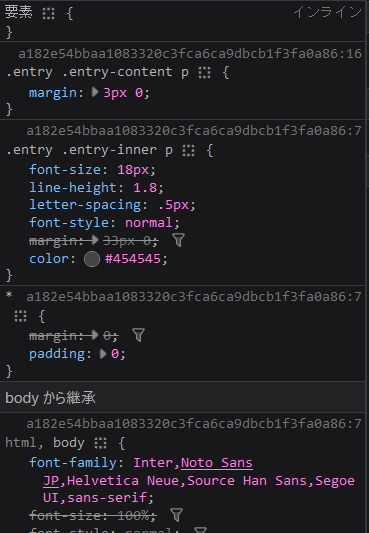
html要素を調査
調査ツールの中央付近にhtml要素に適用されたCSSが表示されます。
上から優先度の高いCSSが表示されています。
1番目の「.entry .entry-content p {」はデザインCSSに設定した内容で、marginをカスタマイズしています。
2番目の「.entry .entry-content p {」はテーマの内容で、カスタマイズ前のmarginが取り消されていることが確認できます。
まとめ
CSSによる書式の変更がうまくいかないときは、調査ツールを起動して調査するのが良いと思います。
調査ツールで設定値をある程度書き換えたりもできるのでいろいろ試すと面白いと思います。
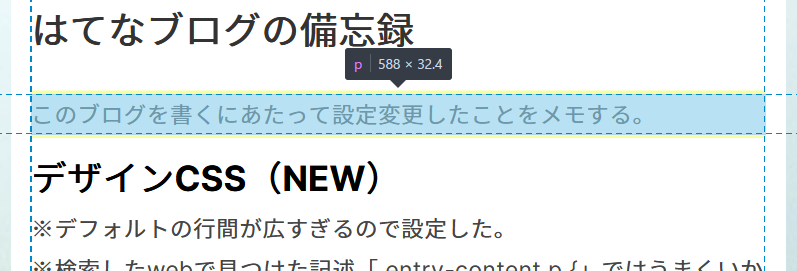
はてなブログの備忘録
このブログを書くにあたって設定変更したことをメモする。
デザインCSS(NEW)
※デフォルトの行間が広すぎるので設定した。
※検索したwebで見つけた記述「.entry-content p {」ではうまくいかず、さらに探した結果「.entry .entry-content p {」とした。
※h1~h6要素のマージンも気に入らなかったのでカスタマイズした。(2023-3-26追記)
※pre要素のマージンも気に入らなかったのでカスタマイズした。(2023-4-2追記)
/* p要素の行間を狭める */ .entry .entry-content p { margin: 3px 0; } /* h1~h6要素行間を狭める */ .entry .entry-inner h1 { margin: 12px 0px 6px 0px; } .entry .entry-inner h2 { margin: 12px 0px 6px 0px; } .entry .entry-inner h3 { margin: 12px 0px 6px 0px; } .entry .entry-inner h4 { margin: 12px 0px 6px 0px; } .entry .entry-inner h5 { margin: 12px 0px 6px 0px; } .entry .entry-inner h6 { margin: 12px 0px 6px 0px; } /* pre要素の行間を狭める */ .entry .entry-content pre { margin: 3px 0; }
デザインCSS(OLD)
※マークダウン記法に移行する前はpre要素について設定していました。
/* 行間を狭める */ .entry .entry-content p { margin: 3px 0; } /* コード貼り付けの1行目を目立たなくする */ .entry .entry-inner pre { padding-top: 0px; padding-bottom: 24px; /* codeの1行に合わせている */ }
コードブロック
※markdown記法で フェンスコード・ブロック を使うとシンタックスハイライトしてくれたので今後はmarkdown記法を推していく。
```javascript // 内容 ```
リンク(markdown)
※プレビューでは表示されないが、ブログを公開したら動作する様子です。
※ただし「 target="_blank" rel="noopener"」が書けないので、元のwebページの表示をやめてリンク先に遷移します。
リンク先は [ここ](https://hatenablog.com/) です。
実際のリンク→「リンク先は ここ です。」
リンク(html)
※プレビューでも動作する様子です。
※「 target="_blank" rel="noopener"」を書きたいのでmarkdown記法でもこちらを推していきます。
リンク先は <a href="https://hatenablog.com/" target="_blank" rel="noopener">ここ</a> です。
実際のリンク→「リンク先は ここ です。」
Octaveを使ってみた件
とりあえず開設。
基本的には、趣味で調べたことを書いていこうと思います。
早速ですが Octave を使ってみた件です。
ダウンロードは GNU Octave から行えます。
ダウンロードは、Linux版、BSD版、MAC版、Windows版、そしてソースコードのダウンロードもできるようです。
さて、何のためだったのかというと、
浮動小数点のメモリイメージが何を示しているのか調べたかったので、
方法を調べたときにヒットした hex2num を試してみたかったからです。
ほかにも javascriptで変換する物 とかあったのですが、
また別途書くことにします。
インストールとか設定は日本語で解説されたページなどもあるのでそちらに譲ることにして本題です。
まず「pi」ですが、おなじみの円周率です。
そして「num2hex(pi)」は、円周率を浮動小数点のメモリイメージに変換しています。
最後に「hex2num(num2hex(pi))」は、浮動小数点のメモリイメージを数値に変換しています。
>> pi
ans = 3.1416
>> num2hex(pi)
ans = 400921fb54442d18
>> hex2num(num2hex(pi))
ans = 3.1416
これを応用して大量のHEXも変換できます。